
La question de l’identité, de l’identification et de l’authentification varie considérablement, dans le monde, selon la situation personnelle et géographique de chacun. Alors que 1 milliard de personnes sont dans l’incapacité de prouver leur identité, par défaillance des institutions régaliennes, le reste de l’humanité semble impuissant à préserver la sienne pour des raisons commerciales et financières (capitalisme de la surveillance – voir La rem n°50-51, p.69 et n°59, p.102), ou pour des raisons politiques et sécuritaires (lutte contre le terrorisme et blanchiment de capitaux, voir La rem n°18-19, p.14 et n°63, p.28).
L’identité numérique désigne généralement « la capacité à utiliser de façon sécurisée les attributs de son identité pour accéder à un ensemble de ressources ». Or, force est de constater que la sécurité fait cruellement défaut aux systèmes d’identité numérique en question, et qu’il suffit d’une faille, parfois humaine, pour mettre en péril les données de millions voire de milliards de personnes. Selon le site de Troy Hunt (haveibeenpwned.com), plus de 13 milliards de comptes e-mail ont été compromis depuis 2013. En janvier 2024, le chercheur en sécurité Bob Dyachenko a découvert une base de données en ligne de 12 téraoctets d’informations, soit la compilation de 26 milliards de données personnelles réparties dans 3 800 dossiers – chacun correspondant à une violation de données particulière – provenant notamment de Tencent QQ, MySpace, X (ex-Twitter), Deezer, LinkedIn, AdultFriendFinder, Adobe, Dailymotion, Dropbox ou encore Telegram. Se trouvaient également dans cette base de données des documents issus d’organisations gouvernementales situées aux États-Unis, au Brésil, en Allemagne, aux Philippines, en Turquie et dans d’autres pays.
Réseaux sociaux, complémentaires santé, banques, musique ou vidéo, commerce électronique, jeux, stockage de fichiers, livraison de repas… à chaque fois qu’une personne interagit avec un service numérique, elle crée un identifiant, fournit une adresse e-mail, parfois un numéro de téléphone, renseigne son nom et son prénom et y associe un mot de passe pour s’authentifier. Selon le type de service, l’internaute pourra être amené à fournir d’autres informations, comme une adresse postale, une date et un lieu de naissance, un numéro de sécurité sociale, la copie d’un passeport ou d’une carte d’identité, une feuille d’imposition, une attestation d’assurance, etc. Chaque interaction avec un nouveau service en ligne est l’occasion de disséminer un peu plus ses informations personnelles. Selon une étude de NordPass, conduite en 2020 et citée par CNN, un individu possédait à cette époque une centaine de comptes en ligne. Seulement deux ans plus tard, une étude mondiale menée par Dashlane estime qu’une personne utilise désormais 240 comptes en ligne. Or, il s’avère que cette manière de s’identifier et de s’authentifier en ligne est défaillante par conception (by design), le système hypertexte public inventé par Tim Berners-Lee et Robert Cailliau dans les années 1990 n’ayant jamais été conçu pour cela.
L’identité numérique centralisée est obsolète
Le principe selon lequel les personnes s’identifient en ligne repose aujourd’hui sur le fait que les services en ligne collectent les données personnelles de leur clients, patients, administrés, diplômés, citoyens, etc. Il s’agit d’un modèle d’identité numérique dit « centralisé », au sein duquel les attributs de l’identité d’une personne sont gérés en un point unique, par une entité qui en assure tout à la fois la collecte, la sécurisation et l’authentification – et dont ce n’est bien souvent pas le métier. En plus d’éviter d’utiliser le même mot de passe pour des dizaines ou des centaines de services différents, chacun doit, en outre, faire confiance à cette entité pour protéger ses informations personnelles et s’assurer que son identité est utilisée de façon appropriée.
Or, ce modèle souffre d’un manque de transparence, d’un manque de contrôle par l’utilisateur, d’un potentiel de surveillance de masse, et surtout des risques encourus en matière de confidentialité et de protection des données en raison d’une trop grande vulnérabilité, chaque service en ligne constituant un point de défaillance. Le modèle actuel est donc devenu obsolète. Les vols de données, les usurpations d’identité (chaque année, en France, près de 400 000 personnes en seraient victimes) et les coûts engendrés par de tels systèmes suscitent depuis longtemps l’intérêt des ingénieurs et des cryptographes.
Vers une identité numérique décentralisée
Par opposition, l’identité numérique décentralisée est un système qui permet à quiconque de stocker et de gérer personnellement les attributs de son identité, émis par des tiers (émetteurs), et de les partager de manière autonome, sélective et parfois anonyme avec d’autres tiers (vérificateurs) afin d’utiliser leurs services, regagnant ainsi une forme de souveraineté à l’échelle individuelle, que la numérisation de la société a tendance à avoir fait disparaître.
Un système d’identité numérique décentralisée, parfois appelée « identité auto-souveraine » (self sovereign identity) propose d’inverser le modèle actuel fondé sur l’authentification et le contrôle d’accès gérés tous deux par une seule organisation, vers un modèle tripartite fondé sur une collection d’attestations vérifiables, constitutives de l’identité numérique d’une personne.
Ce concept repose sur l’idée que chaque individu devrait avoir le contrôle exclusif de son identité numérique, sans dépendre d’une autorité centrale ou d’un tiers de confiance pour s’identifier ou s’authentifier.
L’identité numérique décentralisée est centrée sur l’individu, et se fonde sur les principes de souveraineté, de portabilité et de sécurité. Le modèle d’identité décentralisée requiert d’une personne qu’elle détienne personnellement un logiciel appelé « portefeuille d’identité ». C’est un service numérique, une application qui permet de détenir et de gérer un ou des « identifiants décentralisés » (DID), et de recevoir des « attestations vérifiables » (en anglais Verifiable Credentials, VC) associées à ces identifiants. Ces attestions vérifiables sont l’équivalent numérique d’attestations imprimées, comme un permis de conduire atteste de notre aptitude à conduire un véhicule ou comme un diplôme universitaire atteste d’un niveau d’études.
Une attestation dite « vérifiable » fournit un mécanisme en ligne, respectueux de la vie privée, permettant de représenter cryptographiquement ces justificatifs afin qu’ils soient extrêmement complexes à falsifier tout en étant facilement vérifiables à l’aide d’un programme informatique.
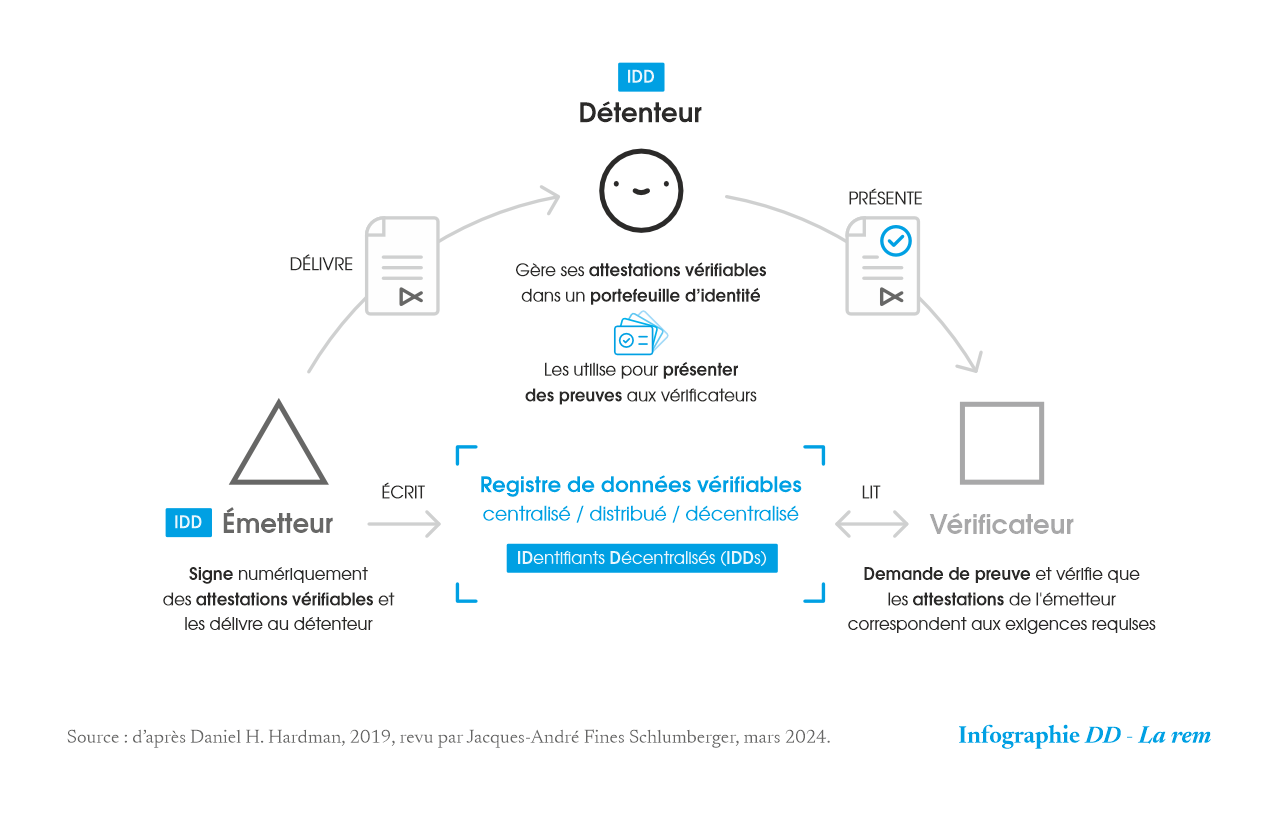
Le modèle d’identité décentralisée fait interagir trois entités :
- le détenteur (holder) est une entité, comme un étudiant, une personne, un employé, qui acquiert, conserve, un ou plusieurs identifiants décentralisés, suivant ses besoins et les services auxquels il veut accéder.
- l’émetteur (issuer) est une entité, comme une entre- prise, une ONG, un gouvernement, une université, un club de pétanque, qui certifie certains champs de cette identité en signant électroniquement les attestations vérifiables : nom, âge, pays de naissance, avoirs bancaires, adhésion à jour etc. Ces champs ne sont pas nécessairement tous présents dans un même identifiant décentralisé, et une personne aura de nombreux identifiants décentralisés différents. Par exemple, un identifiant décentralisé civique peut encoder l’état civil d’une personne, alors qu’un identifiant décentralisé bancaire pourrait encoder des informations relatives à un numéro de compte. Sur la base d’un identifiant décentralisé, son détenteur peut générer une attestation vérifiable, qui est l’énoncé d’un fait portant sur un ou plusieurs champs de l’identifiant décentralisé, qui restent secrets. Par exemple, sur la base d’un identifiant décentralisé civique, une personne peut fournir un justificatif de majorité sans révéler son âge. Sur la base d’un identifiant décentralisé bancaire, une personne peut prouver sa solvabilité sans révéler son nom ni le montant de son compte en banque.
- le vérificateur (verifier) est une entité, comme un employeur, les forces de l’ordre ou un service. Il reçoit une attestation vérifiable et la contrôle suivant « la technique de vérification de preuves à divulgation nulle de connaissance », ZKP pour Zero Knowledge Proof, technique cryptographique qui permet à une partie (le détenteur) de prouver à une autre partie (le vérificateur) qu’elle possède certaines caractéristiques ou qu’elle a effectué certaines actions, sans révéler aucune autre information que le strict nécessaire. Plutôt que d’avoir une pièce d’identité sur laquelle figurent le nom, le prénom, la date et ville de naissance, la taille, la ville de délivrance, etc., une personne génère et présente une attestation vérifiable sur son âge à un tiers qui, en la vérifiant, n’aura accès à aucune autre information que la réponse par « oui » ou par « non » pour savoir si cette personne a plus de 18 ou de 21 ans.
Le terme générique d’identité décentralisée recouvre l’ensemble des systèmes d’identité dont le contrôle ne dépend pas d’une seule entité. Parmi eux, une variante met l’accent sur l’autonomie et sur le contrôle de l’utilisateur : l’identité auto-souveraine ou self-sovereign identity. Né dans les années 1990, ce concept est issu de la communauté des cypherpunks, mot-valise formé à partir de cipher, chiffrement, et de cyberpunk, un genre de science-fiction porté sur les technologies de l’information et leur impact sur la société. Les cypherpunks prônent la cryptographie forte et l’utilisation de technologies décentralisées afin de protéger les libertés fondamentales que sont le droit à la vie privée et le droit à l’anonymat, notamment face à l’intrusion et à la surveillance des communications privées opérées par les gouvernements et par les entreprises.
Parmi les grandes figures de cette communauté se trouvent Timothy C. May, auteur du « Crypto Anarchist Manifesto » en 1988, Eric Hughes, auteur du « Cypherpunk’s Manifesto » en 1993, Phil Zimmermann, cryptographe américain, créateur du logiciel de chiffrement Pretty Good Privacy (PGP) en 1991, Julian Assange, cofondateur de WikiLeaks en 2006 ou encore Hal Finney, ingénieur logiciel et cryptographe américain, l’un des premiers développeurs informatiques du protocole Bitcoin. Leur mouvement travaille à la sécurisation des communications électroniques, à l’invention de systèmes de communication anonyme, à la mise en œuvre des signatures numériques ou au développement de logiciels de chiffrement.
Dans les années 2010, l’identité auto-souveraine a gagné en popularité, avec l’émergence des registres distribués de type blockchain (voir La rem n°44, p.97), à l’origine de l’infrastructure décentralisée, qui a permis sa mise en œuvre. Les 21 et 22 mai 2015, lors de l’IEEE Symposium on Security and Privacy Workshops (SPW), important événement organisé chaque année par l’Institute of Electrical and Electronics Engineers (IEEE), Guy Zyskind, Oz Nathan et Alex « Sandy » Pentland présentent une méthode inspirée de Bitcoin et des blockchains dans une proposition intitulée « Decentralizing Privacy: Using Blockchain to Protect Personal Data » et selon laquelle « les données personnelles, et les données sensibles en général, ne devraient pas être confiées à des tiers, car elles sont susceptibles d’être attaquées et utilisées à mauvais escient. Au contraire, les utilisateurs devraient posséder et contrôler leurs données sans compromettre la sécurité ou limiter la capacité des entreprises et des autorités à fournir des services personnalisés ».
Des standards mondiaux et open source
Cette idée de mettre en œuvre un protocole qui transforme une blockchain en un gestionnaire d’accès automatisé ne nécessitant pas de tiers de confiance, tout en garantissant aux utilisateurs de posséder, maîtriser et contrôler leurs données, va progressivement faire l’objet d’une mobilisation mondiale réunissant des développeurs, des chercheurs, des designers, des militants, des artistes et des citoyens éclairés. Il s’agit ni plus ni moins de repenser la manière dont la confiance est établie et vérifiée sur internet. Cette mobilisation s’est faite notamment au sein de la Decentralized Identity Foundation (DIF), organisation à but non lucratif fondée en 2016, par le biais d’évènements et d’ateliers appelés « Rebooting the Web of Trust » initiés dès 2017, et avec la Trust over IP Foundation (ToIP), organisation à but non lucratif créée en 2019.
Le 29 avril 2016, Christopher Allen, cryptographe et cypherpunk de renommée mondiale, publie l’article « The Path to Self-Sovereign Identity » et détaille les dix principes fondamentaux de l’identité décentralisée, qui influenceront profondément le développement de projets et d’initiatives en la matière. « Les utilisateurs doivent avoir une (1) existence indépendante qui n’est pas contrôlée par une seule entité. Les utilisateurs doivent avoir le (2) contrôle sur leur propre identité et leurs données personnelles. Les utilisateurs doivent avoir (3) accès à leur propre identité et à leurs données personnelles. Les systèmes d’identité doivent être (4) transparents et compréhensibles pour les utilisateurs. Les identités doivent être (5) persistantes et durables dans le temps. Les utilisateurs doivent pouvoir (6) emporter leur identité et leurs données personnelles avec eux lorsqu’ils changent de fournisseur de services. Les systèmes d’identité doivent être (7) interopérables et fonctionner ensemble de manière transparente. Les utilisateurs doivent donner leur (8) consentement éclairé avant que leurs données personnelles ne soient partagées ou utilisées. Les systèmes d’identité doivent (9) minimiser la collecte et le stockage de données personnelles. Les systèmes d’identité doivent (10) protéger les données personnelles des utilisateurs contre les violations de données et les utilisations abusives. »
En juin 2019, le W3C, organisme de standardisation à but non lucratif assurant la compatibilité des techno- logies du World Wide Web, publie la spécification « Decentralized Identifiers (DIDs) v1.0 » en tant que recommandation, mise à jour le 19 juillet 2022. Elle définit un modèle de données et une syntaxe pour les identifiants décentralisés, des identifiants uniques et persistants pour les entités (personnes, organisations, objets, etc.) qui ne dépendent pas d’une autorité centrale. Quiconque a déjà tapé l’adresse d’un site web dans un navigateur web reconnaît le principe de « http », qui veut dire HyperText Transfer Protocol. « http » est le schéma d’URI – (Uniform Resource Identifier), le format d’identifiant standard pour toutes les ressources accessibles sur le World Wide Web, des URL, Uniform Ressource Locator, qui indique la localisation d’une ressource sur le web : « DID » pour Decentralized IDentifiers est, de manière similaire, le schéma d’un format d’identifiant standard pour des « identifiants décentralisés » qui peuvent désigner des personnes, des choses, des objets ou n’importe quelle autre entité. Concrètement, c’est une chaîne de textes et de nombres composée de trois parties : l’identifiant du schéma URL de l’identifiant décentralisé (DID), l’identifiant de la méthode de l’identifiant décentralisé et enfin, l’identifiant décentralisé, lui-même.

Ces identifiants décentralisés sont un nouveau type d’identifiant, qui permettent de mettre en œuvre une identité numérique vérifiable et décentralisée.
Un identifiant décentralisé peut donc être vu comme un lien qui pointe vers un document complet contenant les champs de l’identifiant décentralisé cryptographiquement protégé. Ce document est stocké dans un registre de données vérifiables (Verifiable Data Registry) dont la nature peut varier, entre un registre centralisé, distribué ou décentralisé. Comme nous avons aujourd’hui des centaines de logins et de mots de passe, nous aurons probablement à l’avenir des centaines voire des milliers d’identifiants décentralisés. Chacun d’entre eux nous donnera un canal privé crypté avec une autre personne, une organisation ou un objet. Il n’y aura pas d’autorité centrale d’enregistrement ; chaque identifiant décentra- lisé étant enregistré directement par une personne, idéalement sur une blockchain publique afin que le registre de données vérifiables soit le moins corruptible possible.
À partir de ses identifiants décentralisés, stockés dans un portefeuille d’identité, une personne prouve, à l’aide d’attestations vérifiables qu’il sélectionne, ce qu’il sait (comme un diplôme, une autorisation d’exercer un métier, une certification), ce qu’il a (comme un compte bancaire, sa solvabilité, une citoyenneté), ce qu’il possède (comme un terrain, une résidence, un véhicule), qui il est (comme sa taille, son poids, son âge), ce qu’il fait (comme un emploi, passé ou présent), où il est allé (comme sa participation à un évènement, s’il a été ou non vacciné contre le Covid- 19, etc.). Cependant, il n’envoie plus la copie d’un diplôme, d’un passeport, d’un justificatif de revenus, d’un titre de propriété, d’une carte grise, d’une attestation d’employeur… autant de données personnelles disséminées de façon hasardeuse. En revanche, il dispose de l’ensemble de ses identifiants décentralisés dans un porte- feuille d’identité, comme autant d’attributs propres à son identité numérique, à partir desquels il génère, de manière sélective et temporelle, des attestations vérifiables afin de les présenter à des acteurs identifiés qui en vérifieront, cryptographiquement, la véracité.
Le concept d’identité renvoie à une double reconnaissance, à la fois de soi-même et par les autres. Être au monde et faire société ne se recouvrent pas forcément : les Nations Unies parlent des « invisibles » et un rapport de l’Unicef de 2023 indique qu’« un enfant sur quatre de moins de cinq ans n’existe pas officiellement ». Et pourtant, être en mesure de prouver son identité, c’est accéder à « la capacité d’entrer en relation ». Les systèmes d’identité décentralisée sont extrêmement immatures et déployés nulle part à grande échelle. Même s’il existe des normes communes, la diversité des méthodes empêche actuellement leur interopérabilité, ce qui freine leur adoption, qui, pour être efficace, devrait faire l’objet d’une appropriation massive tout à la fois par les individus, les entreprises et les gouvernements. Or, il n’en est rien. La pérennité des infrastructures sous-jacentes, telles que les registres distribués, est également essentielle pour garantir la disponibilité et la fiabilité des modèles d’identité décentralisée.
Il existe d’innombrables questions dont la plupart sont sans réponse à ce jour. En revanche, ces systèmes sont infiniment moins coûteux à déployer, bien plus sécurisés que les systèmes d’identité centralisée traditionnels. Ils sont les seuls à proposer le regain d’une souveraineté numérique à l’échelle individuelle. Tout le monde et le monde entier y gagneraient, sauf ceux dont le modèle d’affaires repose sur le commerce des données personnelles.
Sources :
- Allen Christopher, « The Path to Self-Sovereign Identity », lifewithalacrity.com, April 26, 2016.
- Hennion Christine, Mis Jean-Michel, « Mission d’information commune sur l’identité numérique », rapport n° 3190, Assemblée nationale, 8 juillet 2020.
- « Verifiable Credentials Data Model v1.1 », W3C Recommendation, w3.org, March 3, 2022.
- « Decentralized Identifiers (DIDs) v1.0, Core architecture, data model, and representations », W3C Recommendation, w3.org, July 19, 2022.
- « A look at Password Health Scores around the world in 2022 », dashlane.com
- Villeroy de Galhau François, « Observatoire de la sécurité des moyens de paiement – Rapport annuel 2021 », Banque de France, juillet 2022.
- Fines Schlumberger Jacques-André, « Rapport Blockchains & développement durable », association de loi 1901 Blockchain for Good, septembre 2022.
- « Censuses and vital registration systems, 2013-2022 », Unicef, mics.unicef.org/surveys, 2023.
- Murphy Kelly Samantha, « We each have an average of 100 online accounts. Here’s how to make sure they aren’t a nightmare for your family if you die », CNN, edition.cnn.com, March 1st, 2024.
